A large crowd of pandas dressed in various colors. The pandas are trying to sort themselves based on their clothing color.MidJourney 5
Getting Started
Before we begin our interactive session, please follow these steps to set up your Jupyter Notebook:
Open JupyterLab and create a new notebook:
Click on the + button in the top left corner
Select Python 3.11.0 from the Notebook options
Rename your notebook:
Right-click on the Untitled.ipynb tab
Select “Rename”
Name your notebook with the format: Session_XY_Topic.ipynb (Replace X with the day number and Y with the session number)
Add a title cell:
In the first cell of your notebook, change the cell type to “Markdown”
Add the following content (replace the placeholders with the actual information):
# Day 6: Session A - Grouping, Joining, and Sorting[Link to session webpage](https://eds-217-essential-python.github.io/course-materials/interactive-sessions/6a_grouping_joining_sorting.html)Date: 09/09/2025
Add a code cell:
Below the title cell, add a new cell
Ensure it’s set as a “Code” cell
This will be where you start writing your Python code for the session
Throughout the session:
Take notes in Markdown cells
Copy or write code in Code cells
Run cells to test your code
Ask questions if you need clarification
Caution
Remember to save your work frequently by clicking the save icon or using the keyboard shortcut (Ctrl+S or Cmd+S).
Let’s begin our interactive session!
Introduction
In this session, we’ll explore essential data manipulation and analysis techniques in pandas, focusing on some simple examples. We’ll cover sorting, grouping, joining, working with dates, and applying custom transformations to data.
Setup
Let’s start by importing the necessary libraries and creating a sample dataset:
Code
import pandas as pdimport numpy as npimport matplotlib.pyplot as plt# Create a sample dataset of species observationsnp.random.seed(42) dates = pd.date_range(start='2023-01-01', periods=100)data = {'date': dates,'site': np.random.choice(['Forest', 'Grassland', 'Wetland'], 100),'species': np.random.choice(['Oak', 'Maple', 'Pine', 'Birch'], 100),'count': np.random.randint(1, 20, 100),'temperature': np.random.normal(15, 5, 100)}df = pd.DataFrame(data)print(df.head())
date site species count temperature
0 2023-01-01 Wetland Birch 7 9.043483
1 2023-01-02 Forest Birch 1 18.282768
2 2023-01-03 Wetland Birch 1 10.126592
3 2023-01-04 Wetland Pine 13 18.935423
4 2023-01-05 Forest Pine 9 20.792978
1. Sorting Data
Sorting is crucial in data analysis for identifying extremes, patterns, and organizing your data for subsequent analyses.
Basic Sorting
Code
# Sort by species countdf_sorted = df.sort_values('count', ascending=False)print(df_sorted.head())
date site species count temperature
12 2023-01-13 Forest Oak 19 10.552428
33 2023-02-03 Grassland Maple 19 19.281994
53 2023-02-23 Forest Maple 19 20.677828
55 2023-02-25 Wetland Birch 19 18.256956
81 2023-03-23 Forest Birch 19 19.262167
Multi-column Sorting
Code
# Sort by site and then by species countdf_multi_sorted = df.sort_values(['site', 'count'], ascending=[True, False])print(df_multi_sorted.head())
date site species count temperature
12 2023-01-13 Forest Oak 19 10.552428
53 2023-02-23 Forest Maple 19 20.677828
81 2023-03-23 Forest Birch 19 19.262167
61 2023-03-03 Forest Oak 18 15.409371
95 2023-04-06 Forest Maple 18 20.162326
2. Grouping and Aggregating Data
Grouping allows us to analyze data at different ecological levels, from individual species to entire ecosystems.
Basic Groupby
Code
# Sum of species counts by sitesite_counts = df.groupby('site')['count'].sum()print(site_counts)
count species temperature
sum mean max nunique mean
site
Forest 311 9.424242 19 4 16.527332
Grassland 336 9.333333 19 4 15.540037
Wetland 248 8.000000 19 4 14.528127
3. Joining Data
Joining data allows us to combine information from datasets.
Code
# Create a second DataFrame with site characteristicssite_data = pd.DataFrame({'site': ['Forest', 'Grassland', 'Wetland'],'soil_pH': [6.5, 7.2, 6.8],'annual_rainfall': [1200, 800, 1500]})# Perform an inner joinmerged_df = pd.merge(df, site_data, on='site', how='inner')print(merged_df.head())
date site species count temperature soil_pH annual_rainfall
0 2023-01-01 Wetland Birch 7 9.043483 6.8 1500
1 2023-01-02 Forest Birch 1 18.282768 6.5 1200
2 2023-01-03 Wetland Birch 1 10.126592 6.8 1500
3 2023-01-04 Wetland Pine 13 18.935423 6.8 1500
4 2023-01-05 Forest Pine 9 20.792978 6.5 1200
Types of joins and when to use them:
Inner Join: Use when you want to combine two datasets based on a common key, keeping only the records that have matches in both datasets. This is useful when you’re interested in analyzing only the data points that have complete information across both sources.
Left Join: Use when you want to keep all records from the left (primary) dataset and match them with records from the right (secondary) dataset where possible. This is helpful when you want to preserve all information from your main dataset while enriching it with additional data where available.
Right Join: Similar to a left join, but keeps all records from the right dataset. This is less common but can be useful when you want to ensure all records from a secondary dataset are included, even if they don’t have corresponding entries in the primary dataset.
Outer Join: Use when you want to combine all unique records from both datasets, regardless of whether they have matches or not. This creates a comprehensive dataset that includes all information from both sources, filling in with null values where there’s no match.
Use cases: - Combining observation data with site characteristics - Merging disparate datasets that share a location or timestamp.
4. Working with Dates
Date manipulation is crucial for analyzing seasonal patterns, long-term trends, and time-sensitive events.
Code
# Set date as indexdf.set_index('date', inplace=True)print(df.head())# Resample to monthly datamonthly_counts = df.resample('ME')['count'].sum()print(monthly_counts.head())
site species count temperature
date
2023-01-01 Wetland Birch 7 9.043483
2023-01-02 Forest Birch 1 18.282768
2023-01-03 Wetland Birch 1 10.126592
2023-01-04 Wetland Pine 13 18.935423
2023-01-05 Forest Pine 9 20.792978
date
2023-01-31 275
2023-02-28 232
2023-03-31 297
2023-04-30 91
Freq: ME, Name: count, dtype: int64
Understanding inplace=True
The inplace=True parameter modifies the original DataFrame directly:
Code
# Without inplace=True (creates a new DataFrame)df_new = df.reset_index()print("\nNew DataFrame with reset index:")print(df_new.head())print("\nOriginal DataFrame (unchanged):")print(df.head())# With inplace=True (modifies the original DataFrame)df.reset_index(inplace=True)print("\nOriginal DataFrame after reset_index(inplace=True):")print(df.head())
New DataFrame with reset index:
date site species count temperature
0 2023-01-01 Wetland Birch 7 9.043483
1 2023-01-02 Forest Birch 1 18.282768
2 2023-01-03 Wetland Birch 1 10.126592
3 2023-01-04 Wetland Pine 13 18.935423
4 2023-01-05 Forest Pine 9 20.792978
Original DataFrame (unchanged):
site species count temperature
date
2023-01-01 Wetland Birch 7 9.043483
2023-01-02 Forest Birch 1 18.282768
2023-01-03 Wetland Birch 1 10.126592
2023-01-04 Wetland Pine 13 18.935423
2023-01-05 Forest Pine 9 20.792978
Original DataFrame after reset_index(inplace=True):
date site species count temperature
0 2023-01-01 Wetland Birch 7 9.043483
1 2023-01-02 Forest Birch 1 18.282768
2 2023-01-03 Wetland Birch 1 10.126592
3 2023-01-04 Wetland Pine 13 18.935423
4 2023-01-05 Forest Pine 9 20.792978
When to use inplace=True: - When preprocessing large datasets to save memory - In data cleaning pipelines for time series - When you’re sure you won’t need the original version of the data
When not to use inplace=True: - When you need to preserve the original dataset for comparison - In functions where you want to return a modified copy without altering the input - When working with shared datasets that other parts of your analysis might depend on
Date Filtering and Analysis
Code
# Filter by date range (e.g., spring season)spring_data = df[(df['date'] >='2023-03-01') & (df['date'] <'2023-06-01')]print(spring_data.head())# Extract date componentsdf['month'] = df['date'].dt.monthdf['day_of_year'] = df['date'].dt.dayofyearprint(df.head())
date site species count temperature
59 2023-03-01 Wetland Birch 8 13.815907
60 2023-03-02 Grassland Pine 7 12.573182
61 2023-03-03 Forest Oak 18 15.409371
62 2023-03-04 Grassland Birch 8 26.573293
63 2023-03-05 Grassland Oak 1 5.663674
date site species count temperature month day_of_year
0 2023-01-01 Wetland Birch 7 9.043483 1 1
1 2023-01-02 Forest Birch 1 18.282768 1 2
2 2023-01-03 Wetland Birch 1 10.126592 1 3
3 2023-01-04 Wetland Pine 13 18.935423 1 4
4 2023-01-05 Forest Pine 9 20.792978 1 5
When to use date manipulation: - Analyzing seasonal patterns - Studying time-specific events (e.g., flowering times, migration patterns) - Creating time-based features for models - Aligning climate data with other observations (resampling)
5. Using df.apply() to transform data
The apply() function allows you to apply custom calculations to your data.
Code
# Apply a function to categorize temperaturedef categorize_temperature(value):if value <10:return'Cold'elif value <20:return'Moderate'else:return'Warm'df['temp_category'] = df['temperature'].apply(categorize_temperature)print(df.head())# Apply a function to calculate biodiversity indexdef simpson_diversity(row): n = row['count'] N = df.loc[df['site'] == row['site'], 'count'].sum()return1- (n * (n -1)) / (N * (N -1))df['simpson_index'] = df.apply(simpson_diversity, axis=1)print(df.head())
When to use apply(): - Calculating complex indices (e.g., biodiversity measures) - Applying models to observational data - Implementing custom data cleaning rules - Performing category-specific calculations
Remember, while apply() is versatile, it can be slower than vectorized operations for large datasets. Always consider if there’s a vectorized alternative, especially when working with big datasets.
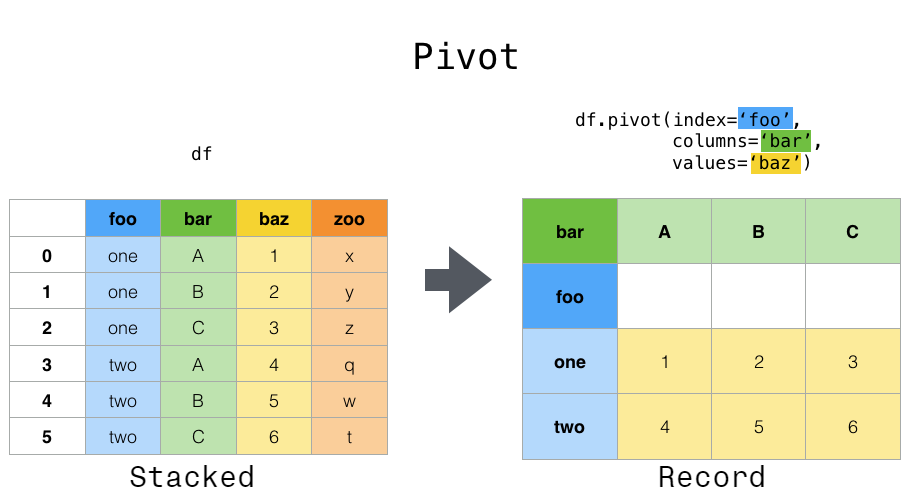
6. Reshaping DataFrames with Pivot Tables
Pivot tables provide a way to reshape data and calculate aggregations in one step.
How Pivot Tables Work
Reshaping Data: Pivot tables reshape data by turning unique values from one column into multiple columns.
Aggregation: They perform aggregations on a specified value column for each unique group created by the new columns.
Index and Columns: You specify which column to use as the new index, which to use as new columns, and which to aggregate.
The idea is very similar to the df.pivot command:
The main difference between df.pivot and df.pivot_table is that df.pivot_table includes aggregation.
Let’s see an example:
✏️ Try it. Add the cell below to your notebook and run it.
Pivot Table:
city Los Angeles New York
date
2023-01-01 68.0 32.0
2023-01-02 72.0 28.0
In this example: - ‘date’ becomes the index - ‘city’ values become new columns - ‘temperature’ values are aggregated (mean) for each date-city combination
Note
In this example, the result of our pivot and pivot_table commands are essentially the same. Why is that the case? When would we expect different results from these two commands?
Key Features of Pivot Tables
Handling Duplicates: If there are multiple values for a given index-column combination, an aggregation function (like mean, sum, count) must be specified.
Missing Data: Pivot tables can reveal missing data, often filling these gaps with NaN.
Multi-level Index: You can create multi-level indexes and columns for more complex reorganizations.
Flexibility: You can pivot on multiple columns and use multiple value columns.
Pivot tables are especially useful for: - Summarizing large datasets - Creating cross-tabulations - Preparing data for visualization - Identifying patterns or trends across categories
Remember, while pivot tables are powerful, they work best with well-structured data and clear categorical variables.
✏️ Try it. Add the cell below to your notebook and run it.
Code
# Create a pivot tablepivot = df.pivot_table(values='temperature', index='city', columns='date', aggfunc='mean')print(pivot)
date 2023-01-01 2023-01-02
city
Los Angeles 68.0 72.0
New York 32.0 28.0
Try creating a pivot table that shows the maximum humidity for each city and date.
✏️ Try it. Add the cell below to your notebook and then provide your code.
Code
# Your code here
Key Points
Grouping allows us to split data based on categories and perform operations on each group.
The groupby() function is the primary tool for grouping in Pandas.
We can apply various aggregation functions to grouped data.
Multi-level grouping creates a hierarchical index.
Pivot tables offer a way to reshape and aggregate data simultaneously.
Conclusion
These techniques form the foundation of data manipulation and analysis in pandas. By understanding when and how to use each method, you can efficiently process and gain insights from datasets. Next you’ll applying these concepts to different scenarios to strengthen your skills in environmental data science.